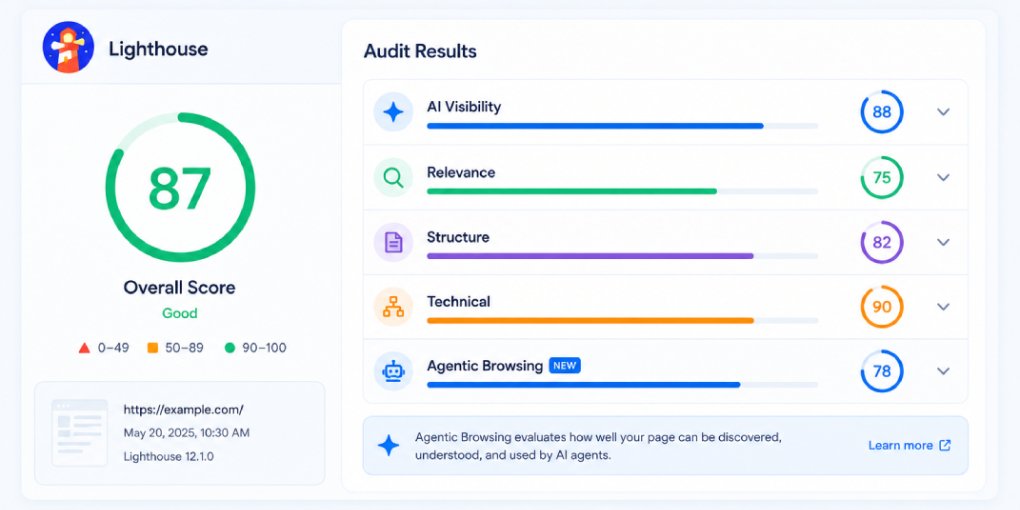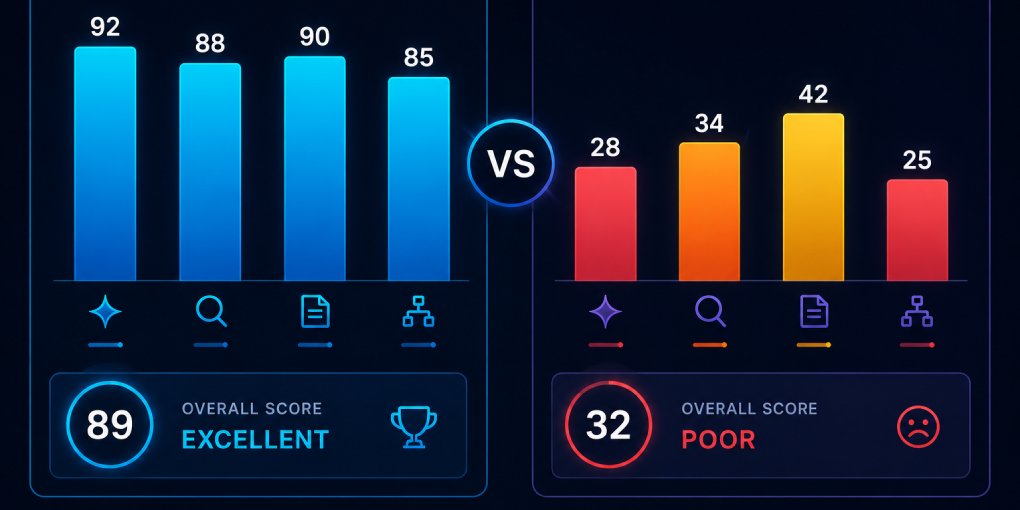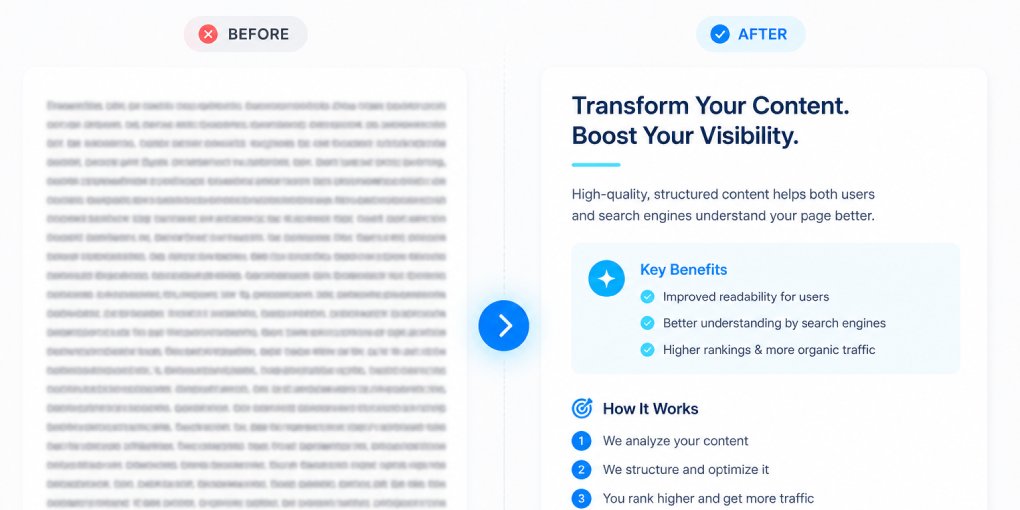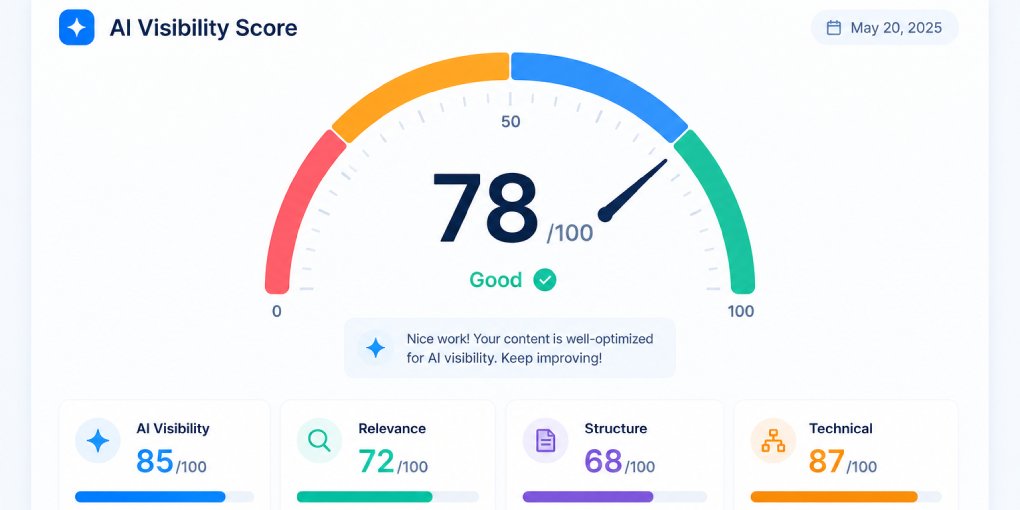
What Is an AI Extractability Score?
You check your Google ranking. You monitor your domain authority. You track your page speed score. But do you know your AI extractability score? It measures something none of those other metrics capture: how easily an LLM can pull usable, citable information from your page.
What the score measures
An AI extractability score quantifies how well your page is structured for machine extraction. Not whether the content is good, but whether it’s packaged in a way that AI models can efficiently parse.
A high score means an LLM can land on your page, quickly identify relevant sections, extract specific answers or statements, and attribute them back to your URL. A low score means the model has to work harder to get usable content, and in most cases, it simply moves to a better-structured competitor instead.
The score isn’t about writing quality or topic authority. A mediocre article with clean structure can outscore a brilliant essay with no headings, no schema, and no metadata. That’s the point: extractability is a structural property, not a content quality judgment.
How it’s calculated
In hey-eye’s scoring system, AI Extractability is the highest-weighted pillar at 35% of the total AI visibility score. It evaluates specific structural signals:
JSON-LD schema. Does the page include structured data that describes the content type, author, publication date, and other metadata? Schema gives models a machine-readable summary before they process the body text. Pages with Article, FAQPage, or HowTo schema score significantly higher.
Paragraph length distribution. How long are your paragraphs? Paragraphs under 100 words extract cleanly as standalone units. Paragraphs over 150 words force models to truncate or summarize, reducing citation accuracy. The score reflects how many of your paragraphs fall within the extractable range.
List usage. Does the page use ordered or unordered lists? Lists are among the most extractable content formats because each item is a self-contained unit. Pages that present multiple items in paragraph form instead of lists score lower.
Date signals. Is there a visible publication or modification date? Date signals tell models how current the content is, which affects whether they choose to cite it. Undated content looks potentially stale.
Internal links. Does the page link to other relevant content on your site? Internal links signal topical depth and help models understand your content’s context within a broader knowledge base.
Breadcrumb markup. Does the page include breadcrumb navigation with structured data? Breadcrumbs tell models where the page sits in your site hierarchy, which adds context to the extracted content.
Definitional patterns. Does the content include clear definitional statements (“X is…”, “X refers to…”)? These patterns produce the cleanest extractions because they’re self-contained, attributable statements.
What score ranges mean
Scores aren’t pass/fail. They exist on a spectrum:
80-100: Excellent. Your content is well-structured for AI extraction. Models can efficiently parse, chunk, and cite your content. Focus on maintaining this level as you publish new content.
60-79: Good. The foundation is solid but there are specific gaps. Usually one or two missing signals (no schema, or paragraphs too long) are pulling the score down. Targeted fixes can push you into the excellent range.
40-59: Needs work. Multiple structural issues are limiting extractability. The model can read your content but has to work hard to extract usable pieces. Competitors with better structure will be cited instead.
Below 40: Poor. Significant structural problems make extraction unreliable. Missing schema, no heading hierarchy, long unstructured paragraphs, or blocked AI crawlers. Comprehensive restructuring is needed.
Why 35% weight
AI Extractability carries the highest weight in hey-eye’s scoring because it directly measures what matters most: can the model actually use your content? Structural Integrity (30%) ensures the page can be parsed. Content Clarity (15%) ensures the text is clean. Authority & Trust (20%) ensures the source is credible. But Extractability is where all of those come together into actual citation potential.
A page with perfect structure, clear writing, and strong trust signals but poor extractability still won’t get cited effectively, because the model can’t isolate the specific content it needs.
Improving your score
The highest-impact fixes, in order:
-
Add JSON-LD schema. Use the hey-eye JSON-LD generator to create the right schema for your content type. This single addition can move your extractability score by 10-15 points.
-
Break long paragraphs. Find every paragraph over 100 words and split it. Each paragraph should make one point that could be quoted independently.
-
Add subheadings. Aim for one H2 or H3 every 200-300 words. Each heading creates a new extractable section.
-
Convert paragraph lists to actual lists. If you’re describing multiple items in prose (“The benefits include X, Y, and Z”), convert them to a proper
<ul>or<ol>. Lists extract dramatically better than inline enumerations. -
Add publication dates. Visible dates on every content page signal freshness and give models temporal context for your information.
Check your score now
Run any URL through hey-eye and look at the AI Extractability pillar. The breakdown shows exactly which checks pass and which fail, so you know precisely where to focus your optimization effort.
Your content might already be good enough to get cited. It might just need the structural packaging that makes extraction effortless.