How to Make Content Extractable for LLMs
Every page on the internet is technically readable by an LLM. But readable and extractable are not the same thing. A model can process a wall of unstructured text, but it won’t quote it. It won’t cite it. It won’t surface it in a response. Extractable content is content that an LLM can isolate, understand in context, and confidently attribute to your page.
Here’s how to get there.
Write in extractable units
LLMs don’t extract entire pages. They extract chunks: a paragraph, a definition, a list, a section under a heading. Your job is to make those chunks self-contained.
Each paragraph should express one idea completely. A reader (or a model) should be able to pull any single paragraph from your page and still understand what it says without needing the paragraph before or after it.
This doesn’t mean dumbing things down. It means being precise. Instead of writing “This approach has several benefits,” followed by a paragraph listing them, write “The main benefits of structured data markup are improved citation rates, richer search results, and better content classification by AI models.” That second version is a standalone, quotable unit.
Use definitional patterns
The fastest way to get cited by an LLM is to define something clearly. Models love sentences that follow the pattern “X is…” or “X refers to…” because they can extract and attribute them with high confidence.
If your page covers a concept, define it explicitly within the first two paragraphs. Don’t assume the reader (or the model) knows what you mean. A clear definition near the top of the page dramatically increases the chance of extraction.
Structure with semantic HTML
Headings are not decoration. They are chunk boundaries. Every H2 on your page creates a new extractable section. Every H3 creates a subsection the model can target independently.
Rules to follow:
- One H1 per page, stating the main topic
- H2s for each major section
- H3s for supporting points within a section
- No skipped levels (H1 to H4 breaks the hierarchy)
- No heading used purely for visual styling
Paragraphs should use <p> tags. Lists should use <ul> or <ol>. Tables should use <table>. This sounds obvious, but many sites use <div> tags for everything, which strips the semantic meaning that models rely on.
Add structured data
JSON-LD schema gives LLMs explicit metadata about your content. At minimum, every content page should have Article schema with headline, author, datePublished, and description.
For specific content types, add the matching schema: FAQPage for Q&A content, HowTo for step-by-step guides, Product for product pages. This structured data acts as a machine-readable summary that models can parse before they even process your prose.
Keep paragraphs short
Long paragraphs are hard to extract because they typically contain multiple ideas. When a model tries to quote a 200-word paragraph, it either takes too much or has to summarize, which reduces attribution accuracy.
Aim for 2-3 sentences per paragraph. Each paragraph should be a single, complete thought. This improves both human readability and machine extractability.
Front-load your answers
If your page answers a question, put the answer in the first paragraph. Don’t build up to it. Don’t provide context first. Answer, then explain.
LLMs weight the opening content of a page and each section more heavily. A clear answer in the first sentence of a section is far more likely to be extracted than the same answer buried in the fourth paragraph.
Make trust verifiable
Extractability isn’t just about structure. Models also evaluate whether your content is worth extracting. Trust signals help with this:
- Author name and credentials visible on the page
- Links to an About page
- External citations to authoritative sources
- HTTPS, clean URL structure, fast load times
- Social profile links
These signals don’t directly affect how content is chunked, but they influence whether a model chooses to cite your page over a competitor’s.
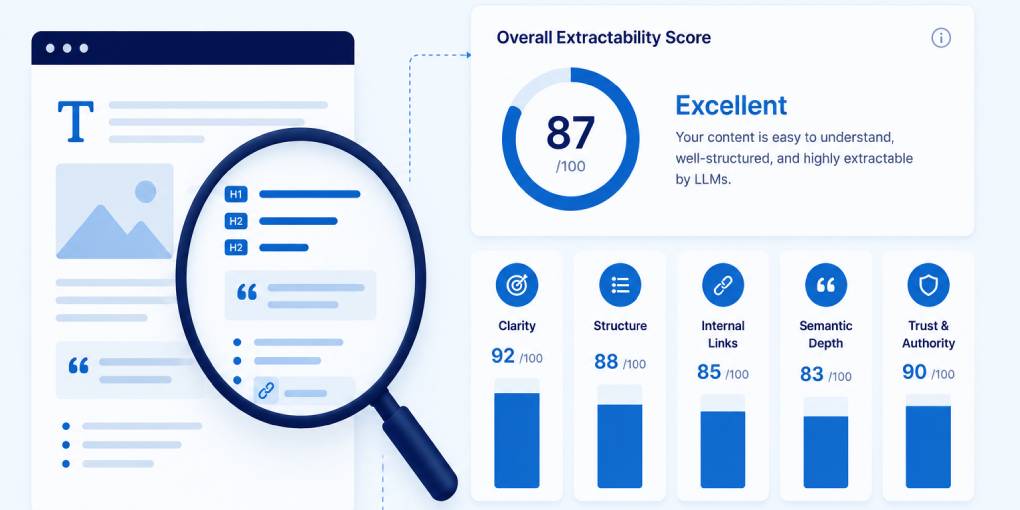
Test and measure
Run your page through hey-eye and focus on the AI Extractability pillar. The score breaks down exactly which structural elements are present or missing. Fix the gaps, re-scan, and track the improvement over time.
Extractability is not about writing for machines. It’s about writing with enough structure that machines can do what they already want to do: find the best answer and tell the user where it came from.