How to Make Your Content LLM-Readable
There’s a difference between content that an LLM can technically process and content that an LLM will actually use. Every page on the internet is technically readable. But most pages force models to work hard to extract meaning from messy HTML, ambiguous structure, and missing metadata. LLM-readable content removes that friction.
The good news: making content LLM-readable doesn’t require rewriting. It requires restructuring.
What LLM-readable actually means
An LLM-readable page is one where a model can land on the HTML, immediately understand what the page is about, identify the key sections, extract specific answers to questions, and attribute the information back to the source. All of this happens through structural signals, not content quality.
A brilliant essay published as a single unbroken block of text inside a generic div with no headings, no schema, and no metadata is less LLM-readable than a mediocre article with clean heading hierarchy, Article schema, and well-organized paragraphs.
Quality determines whether the content is worth citing. Structure determines whether the model can cite it at all.
The five layers of LLM readability
Think of readability as a stack. Each layer builds on the one below it. Skipping a layer weakens everything above it.
Layer 1: Accessible HTML. The model must be able to parse your page. Content rendered entirely in JavaScript, hidden behind login walls, or blocked by robots.txt is invisible. This is the baseline: can the model even read the bytes?
Layer 2: Semantic structure. Proper HTML elements (article, section, nav, aside, header, footer) tell the model what role each content block plays. Generic divs and spans carry no semantic meaning. The model can still parse them, but it’s guessing about context.
Layer 3: Heading hierarchy. H1 for the page topic, H2s for sections, H3s for subsections. This creates a navigable outline that the model uses to locate specific information. Without headings, the model processes your content as one continuous stream with no landmarks.
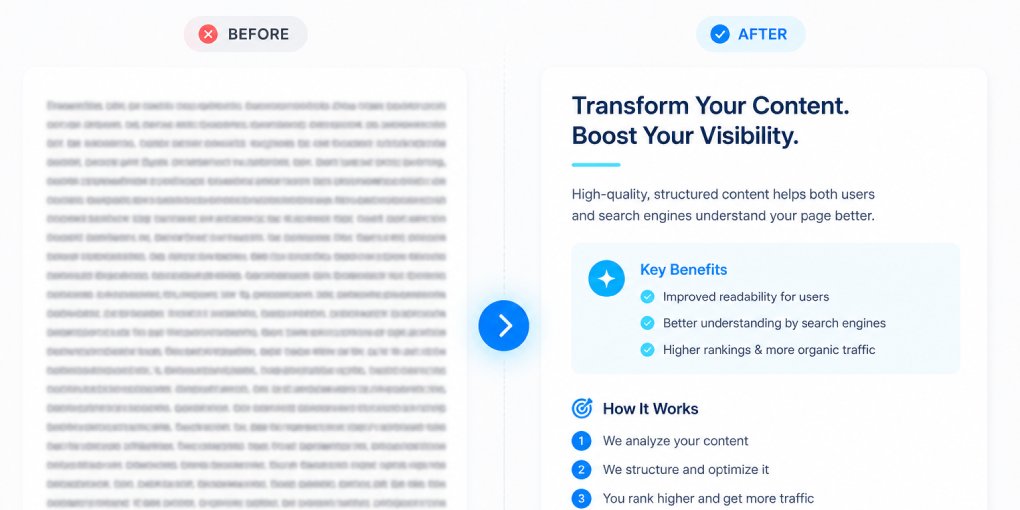
Layer 4: Content chunking. Short paragraphs (2-3 sentences each), one idea per paragraph, self-contained statements that make sense without surrounding context. This is what makes individual pieces of your content quotable and citable.
Layer 5: Machine metadata. JSON-LD schema, Open Graph tags, meta descriptions, canonical URLs. These give the model explicit, structured information about your content before it processes the body text. It’s the difference between the model discovering your page is an article about JSON-LD by reading 2,000 words, and knowing it instantly from a metadata block.
Quick diagnostic
Before optimizing, assess where you stand. Open your page’s source code and answer these questions:
Can you find your main content without scrolling past hundreds of lines of scripts and navigation markup? If not, your content is buried.
Is there a single H1 tag? Count them. More than one creates ambiguity.
Are there H2 tags breaking the content into sections? If your entire article lives under one heading, it’s one giant chunk.
Search for “application/ld+json” in the source. If nothing comes up, you have no structured data.
Disable JavaScript in your browser and reload. Whatever you see is what most AI models see. If the page is blank or broken, your content isn’t accessible to LLMs.
The fastest fixes
If you want to improve LLM readability today, do these four things:
Add Article schema. Use the hey-eye JSON-LD generator to create a schema block. Paste it into your page’s head section. Five minutes, immediate impact.
Break up long sections. Find any section longer than 300 words without a subheading. Add an H2 or H3 at the natural break point. This creates new chunk boundaries that models can target.
Shorten your longest paragraphs. Find paragraphs over 100 words. Split them at the most natural point. Each paragraph should make one point that could be quoted independently.
Check your robots.txt. Visit yoursite.com/robots.txt and look for Disallow rules that might block AI crawlers. If you see GPTBot, ClaudeBot, or Google-Extended being blocked, that’s your biggest problem. Use the hey-eye robots.txt generator to fix it.
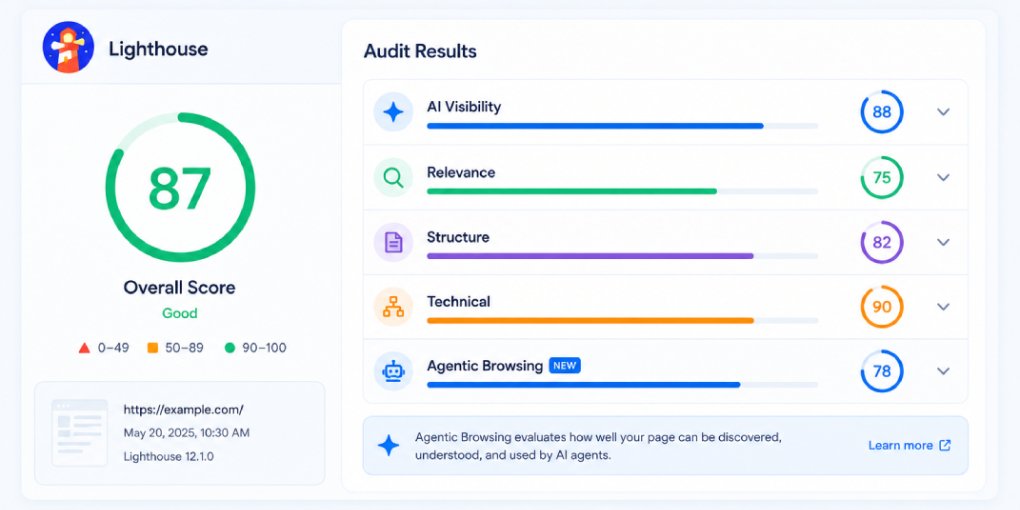
Measuring readability
Run your page through hey-eye and look at all four pillars together. LLM readability isn’t captured by a single score. It’s the combination of Structural Integrity (can the model parse your HTML), AI Extractability (can it chunk and cite your content), Content Clarity (is the text itself clean enough to extract), and Authority & Trust (does the model trust the source).
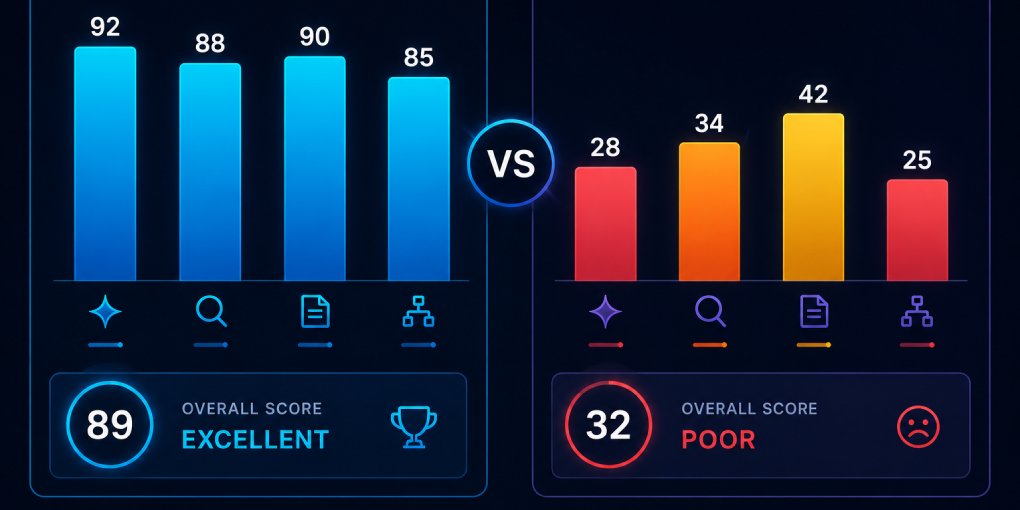
A page that scores well across all four pillars is genuinely LLM-readable. A page that spikes on one but fails on others has gaps in the stack that limit its overall readability.
The goal isn’t perfection on every check. It’s consistency across the stack, because models evaluate the whole package, not individual signals in isolation.