How Can I Measure the Extractability of a Blog Post?
You published a blog post. It’s well-written, covers the topic thoroughly, and ranks decently in Google. But when someone asks ChatGPT or Claude about the same topic, your post doesn’t get mentioned. The problem might not be your content. It might be your extractability.
Extractability is how easily an LLM can isolate specific pieces of your content, understand them in context, and attribute them back to your page. It’s measurable, and once you know what to look for, it’s fixable.
What extractability actually means
Think of extractability as the difference between a book and a filing cabinet. A book contains great information, but finding one specific fact means reading through pages. A filing cabinet organizes the same information into labeled, accessible units. LLMs prefer filing cabinets.
A blog post with high extractability has content that’s organized into clear, self-contained sections. Each section answers a specific question or covers a specific subtopic. The model can pull any section independently without losing meaning.
A post with low extractability buries insights inside long, flowing paragraphs with no structural markers. The content might be excellent, but the model can’t efficiently locate and isolate the parts it needs.
The signals to measure
There’s no single “extractability score” that all LLMs publish. But there are concrete structural signals you can check:
Heading coverage. Count your H2 and H3 tags. A 1,000-word post should have at least 3-4 H2 sections. If you have fewer, your content lacks chunk boundaries. If you have none, the entire post is one undifferentiated block from the model’s perspective.
Paragraph length. Count the words in each paragraph. Paragraphs over 100 words are harder to extract as standalone units. Aim for 40-80 words per paragraph. This isn’t a style preference. It’s a structural requirement for clean extraction.
Definitional density. Scan your post for sentences that follow the “X is…” or “X refers to…” pattern. These are the sentences most likely to be quoted by an LLM. If your post explains a concept but never explicitly defines it, you’re leaving citations on the table.
Schema markup. Check your page source for JSON-LD structured data. At minimum, every blog post should have Article schema with headline, author, datePublished, and description. This metadata gives models explicit context before they even process your prose.
Internal link count. Posts with zero internal links appear isolated. Posts that link to related content on your site signal topical depth and help models map your expertise.
Using hey-eye to measure
Run your blog post URL through hey-eye and look at the four-pillar breakdown:
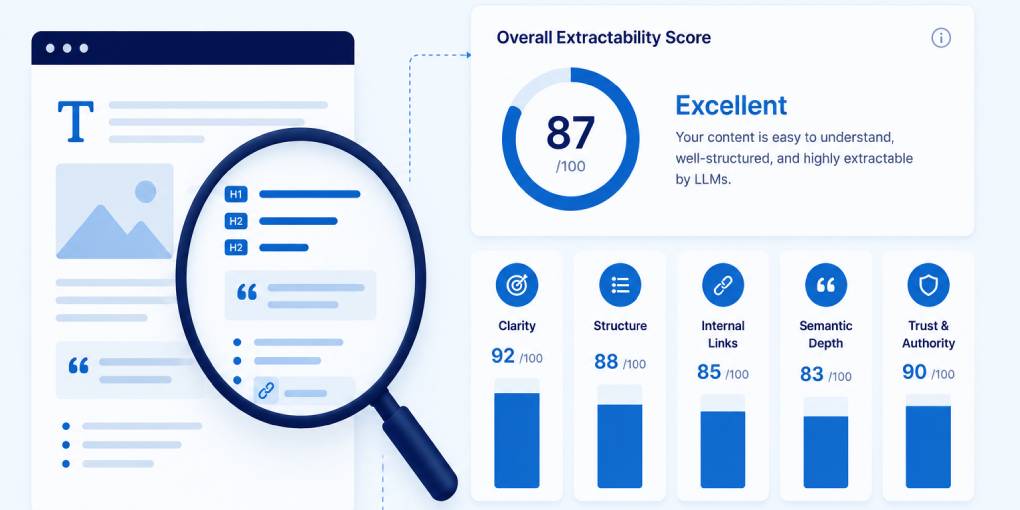
AI Extractability (35% weight) is the most directly relevant pillar. It checks for JSON-LD schema, paragraph length distribution, list usage, date signals, internal links, and breadcrumb markup. This pillar tells you how machine-readable your content structure is.
Structural Integrity (30% weight) checks your heading hierarchy, canonical tags, Open Graph markup, and semantic HTML. Poor structural integrity means the model struggles to parse your page before it even reaches the content.
Content Clarity (15% weight) measures sentence length, heading density, and readability. High clarity scores mean your content is easy to chunk into quotable segments.
Authority & Trust (20% weight) evaluates author attribution, social profiles, about page links, and robots.txt configuration. This pillar influences whether a model trusts your content enough to cite it.
A balanced score across all four pillars is better than a spike in one. If your AI Extractability score is 90 but your Structural Integrity is 40, the model can extract your content but may struggle to parse the page correctly in the first place.
A quick self-audit
Before you run any tool, you can do a 60-second manual check:
- Read only your headings top to bottom. Do they form a logical outline?
- Pick any paragraph at random. Does it make sense without reading the one before it?
- Search your post for “is a” or “refers to.” Did you define your key terms?
- View page source and search for “application/ld+json.” Is there schema markup?
- Count your internal links. Are there at least two pointing to related content?
If you answered no to more than two of these, your extractability has room to improve, and the fixes are usually straightforward structural changes that take minutes, not hours.
Measure, fix, measure again
Extractability isn’t static. Every edit you make changes it. The most effective workflow is: scan your post, identify the weakest pillar, fix the top issues, and re-scan. Track the score over time using Scan History to see whether your structural improvements are having the intended effect.
The content you’ve already written might be good enough to get cited by LLMs. It might just need better packaging.